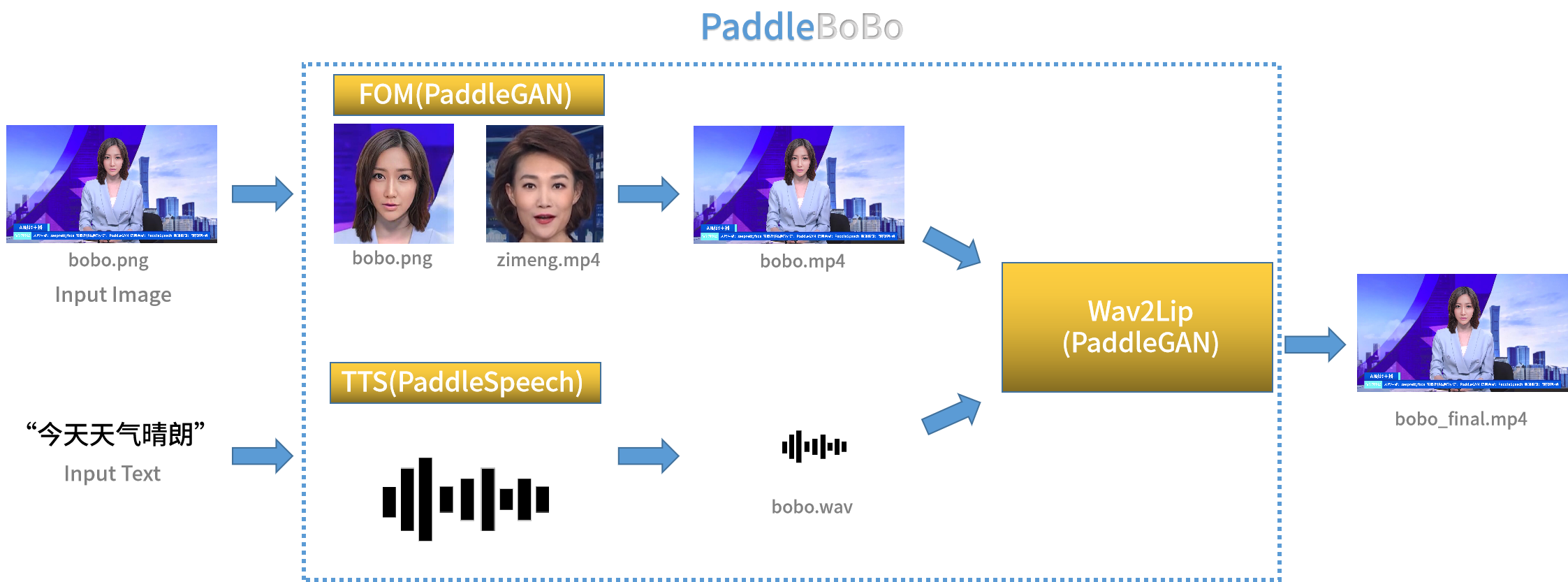
金融AIGC研究
搜索



优质 高效
优质的技术交付服务 迅捷的办事效率
优质的技术交付服务 迅捷的办事效率
我们专注品质与服务 决胜制高点 细节决定成败
Runoff commanding heights Detail decides success or failure
The commanding heights of
the details determine success or failure
Runoff commanding heights Detail decides success or failure
The commanding heights of
the details determine success or failure

技术动态
DETAIL